Feature Views
In Tecton, features are defined as a view on registered Data Sources or other Feature Views. Feature Views are the core abstraction that enables:
- Using one feature definition for both training and serving.
- Reusing features across models.
- Managing feature lineage and versioning.
- Orchestrating compute and storage of features.
Feature View contains all information required to manage one or more related features, including:
- Pipeline: A transformation pipeline that takes in one or more inputs and runs transformations to compute features. Inputs can be Tecton Data Sources or in some cases, other Feature Views.
- Entities: The common objects that the features are attributes of such as Customer or Product. The entities dictate the join keys for the Feature View.
- Configuration: Materialization configuration for defining the orchestration and serving of features, as well as monitoring configuration.
- Metadata: Optional metadata about the features used for organization and discovery. This can include things like descriptions, families, and tags.
The pipeline and entities for a Feature View define the semantics of what the feature values truly represent. Changes to a Feature View's pipelines or entities are therefore considered destructive and will result in the rematerialization of feature values.
Concept: Feature Views in a Feature Store
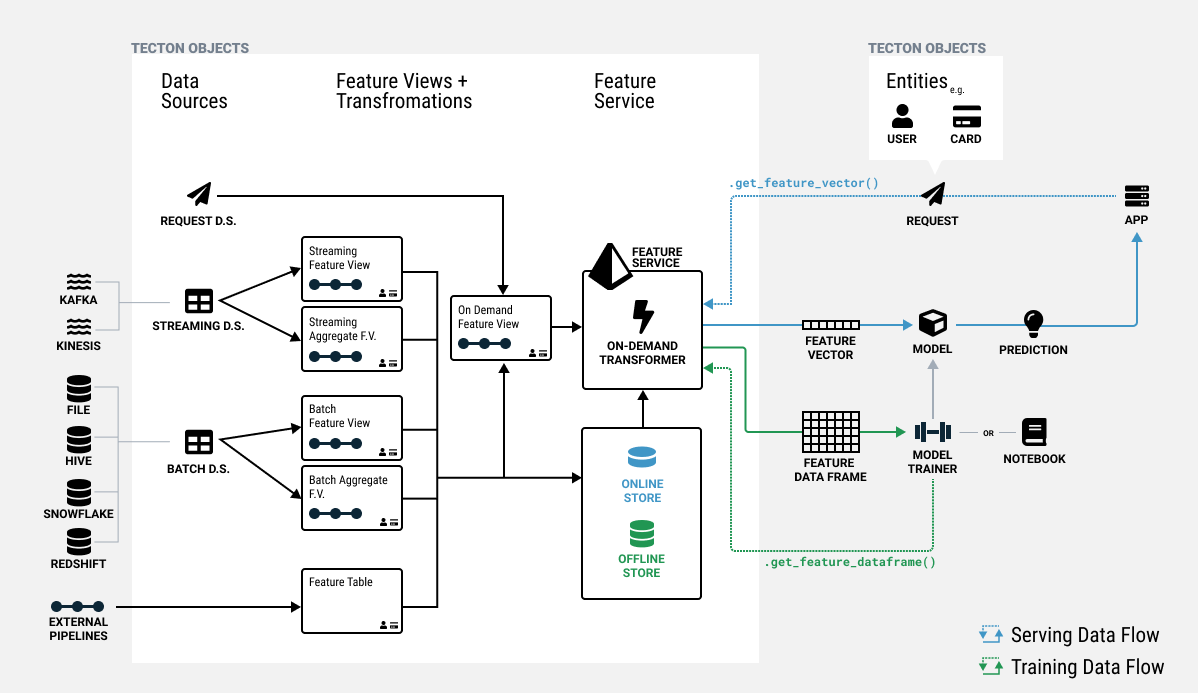
There are different types of Feature Views that can be used to connect to different inputs and run different types of feature data pipelines.
- Batch and Stream Feature Views take Batch and Stream Data Sources as inputs, pass those inputs through a pipeline of transformations, and optionally materialize the data to the Offline and Online Feature Stores for use in training and serving.
- On-Demand Feature Views can take Batch and Stream Feature Views as inputs as well as Request Data Sources, and run a pipeline of transformations at request time to compute new feature values.
- Batch Window Aggregate and Stream Window Aggregate Feature Views are specialized pipelines that are optimized across pre-computation and on-demand computation to create highly efficient and fresh sliding window aggregation features.
Typically a single Feature View will contain a set of related individual features that can easily be expressed within a single query. Feature Views are grouped together in a Feature Service to define the total set of features for training and serving a model.
Types of Feature Views
| Name | When to use | Input types | Transformation types |
|---|---|---|---|
| Batch Feature View | Defining row-level transformations or custom aggregations for batch data sources. | Batch Data Source | pyspark, spark_sql |
| Stream Feature View | Defining row-level or custom aggregations for stream data sources. | Stream Data Source | pyspark, spark_sql |
| Batch Window Aggregate Feature View | Efficiently create multiple time-windowed aggregate features from batch data sources. | Batch Data Source | pyspark, spark_sql, built in time-windowed aggregations |
| Stream Window Aggregate Feature View | Efficiently create multiple time-windowed aggregate features from stream data sources. | Stream Data Source | pyspark, spark_sql, built in time-windowed aggregations |
| On-Demand Feature View | Define features based on request time data, or combine multiple existing features. | Request Data Source, Batch Feature View, Stream Feature View | pandas |
Defining a Feature View
A Feature View is defined using an decorator over a function that represents a pipeline of Transformations.
Below, we'll describe the high-level components of defining a Feature View. See the individual Feature View type sections for more details and examples.
# Feature View type
@batch_feature_view(
# Pipeline attributes
inputs=...
mode=...
# Entities
entities=...
# Materialization and serving configuration
online=...
offline=...
batch_schedule=...
feature_start_time=...
ttl=...
backfill_config=...
# Metadata
owner=...
description=...
tags=...
)
# Feature View name
def my_feature_view(input_data):
intermediate_data = my_transformation(input_data)
output_data = my_transformation_two(intermediate_data)
return output_data
See the API reference for the specific parameters available for each type of Feature View.
Function Definition
Feature Views are registered by adding a decorator (e.g. @batch_feature_view) to a Python function. The decorator supports several parameters to configure the Feature View.
The default name of the Feature View registered with Tecton will be the name of the function. If needed, the name can be explicitly set using the name_override decorator parameter.
The function inputs will be DataFrames retrieved from the specified inputs. Tecton will use the function pipeline definition to construct, register, and execute the specified graph of transformations.
Ultimately, the transformation pipeline output must produce a DataFrame.
Pipeline Definition
The body of a Feature View function calls Transformations that define features. The data sources configured by the decorator parameters will be made available as inputs to the function.
The output columns of our Feature View DataFrame must include:
- The join keys of all entities included in the
entitieslist - A timestamp column. If there is more than one timestamp column, a
timestamp_keyparameter must be set to specify which column is the correct timestamp of the feature values. - Feature value columns. All columns other than the join keys and timestamp will be considered features in a Feature View.
Important
There are two Feature View pipeline modes: inline and pipeline. This is configured using the mode parameter.
| Mode | Supported mode values |
Description |
|---|---|---|
| Inline | "spark_sql", "pyspark", "pandas" |
Single transformation pipeline declared inline with a Feature View definition. |
| Pipeline | "pipeline" |
1 or more @transformation functions defined separately from a Feature View. |
Inline
Feature Views that only use one Transformation can define the Transformation within the body of the Feature View function. For example, this code snippet is a Feature View with a single Transformation in "spark_sql" mode that simply renames columns from the data source to feature_one and feature_two.
@batch_feature_view(
mode="spark_sql",
...
)
def my_feature_view(input_data):
return f"""
SELECT
entity_id,
timestamp,
column_a AS feature_one,
column_b AS feature_two
FROM {input_data}
"""
Pipeline
For example, the code snippet from above can be rewritten using two functions in "pipeline" mode. Now, the Transformation uses "spark_sql" mode and the Feature View uses "pipeline" mode.
@transformation(mode="spark_sql")
def my_transformation(input_data):
return f"""
SELECT
entity_id,
timestamp,
column_a AS feature_one,
column_b AS feature_two
FROM {input_data}
"""
@batch_feature_view(
mode="pipeline",
...
)
def my_feature_view(input_data):
return my_transformation(input_data)
Multi-Transformation Pipelines
More complicated feature logic can be factored into multiple transformations for readability and reusability. All data operations must be inside a transformation. The transformations for a Feature View cannot contain arbitrary Python code.
In this example, we implement a generic str_split transformation on a specified column, followed by another transformation to calculate some summary statistics for the feature.
Note that passing constants to a transformations requires using const which can be imported from tecton.
Interacting with Feature Views
Once you have applied your Feature View to the Feature Store, the Tecton SDK provides a set of methods that allow you to access a feature in your Notebook. Here are a few examples of common actions.
Retrieving a Feature View Object
First, you'll need to get the feature view with the registered name.
feature_view = tecton.get_feature_view("user_ad_impression_counts")
Running Feature View Transformation Pipeline
You can dry-run the feature view transformation pipeline from the notebook for all types of feature view.
result_dataframe = feature_view.run()
display(result_dataframe.to_spark())
See the API reference for the specific parameters available for each type of Feature View.
For StreamFeatureView and StreamWindowAggregateFeatureViews, you can also run the streaming job. This will write to a temporary table which can be queried
feature_view.run_stream(output_temp_table="temp_table") # start streaming job
display(spark.sql("SELECT * FROM temp_table LIMIT 5"))` # Query the output table
Reading Feature View Data
Reading a sample of feature values can help validate that you've implemented it correctly, or understand the data structure when exploring a feature you're unfamiliar with.
For Batch and Stream features you can use the FeatureView.get_historical_features() method to view some output from your new feature. To help your query run faster, you can use the start_time and end_time parameters to select a subset of dates, or pass an entities DataFrame of keys to view results for just those entity keys.
from datetime import datetime, timedelta
start_time = datetime.today() - timedelta(days=2)
results = feature_view.get_historical_features(start_time=start_time)
display(results)
Because On-Demand Feature Views depend on request data and or other Batch and Stream Feature Views, they cannot simply be looked up from the Feature Store using get_historical_features() without the proper input data. Refer to On-Demand Feature Views for more details on how to test and preview these Feature Views.